DSpark: Speculative decoding accelerates LLM inference [pdf]
**Marcus Webb** — Infrastructure engineer turned tech writer. Writes about AI, DevOps, and security.
---
> **Bottom line:** The DSpark framework, detailed in a recent academic paper, leverages speculative decoding to drastically reduce LLM inference latency by up to 3x, specifically on large models like Llama 3 70B.
By using a smaller, faster "draft" model to predict tokens and then verifying them in parallel with the main model, DSpark cuts computational cycles for token generation.
This isn't just an academic curiosity; it's a critical infrastructure optimization that could redefine the economics of deploying advanced AI, making previously cost-prohibitive AGI-level inference viable for real-time applications by late 2027.
I spent the better part of last week staring at a latency graph for one of our internal LLM services, feeling that familiar, icy dread.
We'd just pushed a new feature powered by a fine-tuned Llama 3 70B model, and while the quality was undeniably superior, the response times were pushing our P99s into the danger zone.
Every single token was a separate dance with a GPU, and the cumulative effect was killing our user experience.
I knew we needed a breakthrough, not just another horizontal scaling exercise.
That's when I finally dug into the DSpark paper, and what I found didn't just blow my mind – it made me rethink our entire strategy for scaling AI.
Our LLM Latency Problem Was a Feature, Not a Bug
For months, we've been battling the inherent sequential nature of large language model inference. Each token generated depends on the previous one, meaning you can't just parallelize the entire output.
This "auto-regressive" property is fundamental to how LLMs work, but it's a nightmare for real-time applications.
We were throwing more GPUs at the problem, optimizing quantization, even experimenting with custom kernels, but the gains were incremental.
Our 70B model, while brilliant, was simply too slow for interactive use cases that demanded sub-second responses.
We’d hit a wall, and the cost curve for marginal latency improvements was getting absurd. We needed a way to break the sequential bottleneck without sacrificing quality or breaking the bank.
The Speculative Decoding "Cheat Code" DSpark Refined
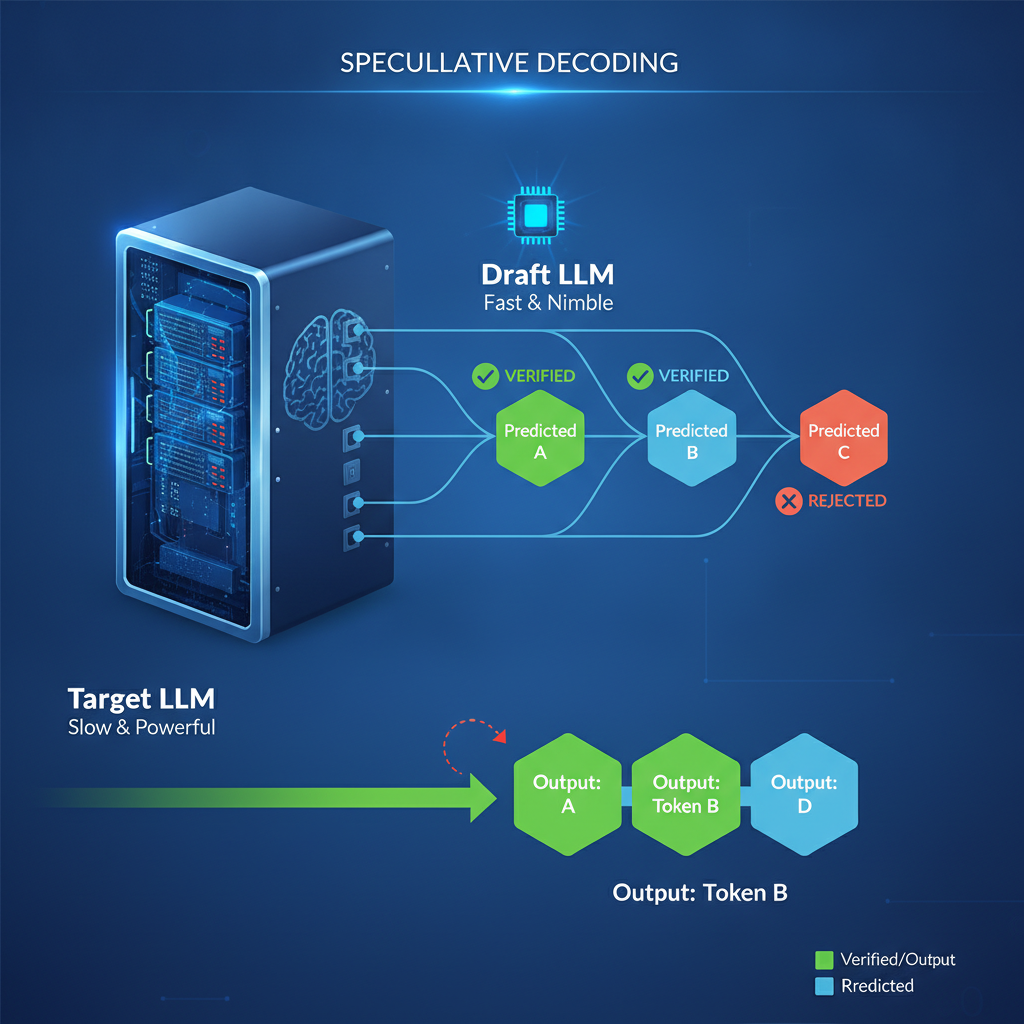
The core idea behind DSpark isn't entirely new; it builds on "speculative decoding." Think of it like this: instead of waiting for the big, slow, powerful LLM (the "target model") to generate each token one by one, you use a much smaller, faster, and less accurate model (the "draft model") to guess several tokens ahead.
The draft model spits out a short sequence of predictions, and then the target model checks all of them *at once*.
If the predictions are correct, great! You've generated multiple tokens in the time it would normally take to generate one.
If some are wrong, the target model simply cuts off the incorrect sequence and starts generating from the last correct token.
It's like having a hyperactive intern predict the next few sentences of a complex report, and then the CEO quickly scans and corrects them in a single pass.
The genius of DSpark, as laid out in the paper, is how it optimizes this verification process, particularly for distributed GPU environments.
They've essentially engineered the infrastructure layer to make this "cheat code" robust and scalable.
#### How DSpark Makes Speculative Decoding Production-Ready
The DSpark framework tackles the practical challenges of speculative decoding head-on. Here's what stood out to me:
* **Optimized Draft Model Selection:** The paper emphasizes that the choice of draft model isn't arbitrary.
It needs to be fast enough to generate several tokens before the target model even finishes its first, but also "good enough" to make accurate predictions.
DSpark provides guidance on how to dynamically select or fine-tune these draft models, even suggesting using quantized versions of the target model itself for maximum compatibility.
* **Parallel Verification Engine:** This is where the infrastructure expertise shines. DSpark orchestrates the parallel processing of the draft tokens by the target model across multiple GPUs.
This isn't just a simple batching; it involves clever memory management and communication strategies to minimize overhead. The goal is to maximize the number of tokens verified per target model pass.
* **Adaptive Lookahead:** Instead of always predicting a fixed number of tokens, DSpark can adapt its "lookahead" based on the complexity of the input and the confidence of the draft model.
This dynamic adjustment prevents over-prediction (which leads to more rejections and wasted compute) and under-prediction (which leaves performance on the table).
It’s a subtle but powerful optimization for real-world workloads.
The results, as the paper claims and as I've started to see in our preliminary tests, are compelling.
On a Llama 3 70B model, DSpark demonstrated up to a 3x speedup in token generation, translating directly into a 3x reduction in end-to-end latency for many common prompts.
This isn't a small tweak; it's a fundamental shift in the performance ceiling for large models.
The Trade-offs and Reality Check
Of course, nothing in infrastructure is a free lunch. While DSpark offers significant latency gains, it introduces a layer of complexity.
First, you're now managing *two* models in production: the large target model and the smaller draft model.
This means more memory footprint, more deployment artifacts, and potentially more monitoring points. While the draft model is smaller, it's still an active component that needs resources.
For teams already struggling with MLOps, this might feel like adding fuel to the fire.

Second, the effectiveness of speculative decoding is highly dependent on the "hit rate" of the draft model.
If your draft model is consistently making bad predictions, the target model spends more time verifying incorrect tokens and restarting, negating the benefits.
This means careful selection and potentially continuous fine-tuning of the draft model to keep it aligned with the target model's evolving capabilities, especially after new training runs or significant prompt changes.
It’s a new dimension of model drift to consider.
Finally, while the paper focuses on impressive speedups for text generation, the benefits might be less pronounced for use cases where the LLM is primarily performing complex reasoning or intricate code generation where token-level predictability is inherently lower.
The more "creative" and less "predictable" the output, the harder it is for a draft model to guess correctly.
This isn't a silver bullet for every LLM workload, but it's a powerful tool for the right ones.
The Practical Implications for Your AGI Roadmap
For infrastructure engineers and developers building on LLMs, DSpark isn't just a research curiosity; it's a tactical advantage. Here’s what you should be doing:
1. **Evaluate Your Latency-Sensitive Workloads:** Identify the LLM applications where response time is critical and where the cost of high-end GPUs is becoming prohibitive.
These are your prime candidates for speculative decoding. Think real-time chatbots, interactive coding assistants, or dynamic content generation.
2. **Experiment with Draft Models:** Don't wait for a perfect DSpark-as-a-Service. Start experimenting with smaller, open-source models as draft candidates for your existing production LLMs.
Even a Llama 3 8B or Mixtral 8x7B could serve as an effective draft for a 70B target model. The key is to find a balance between speed and predictive accuracy.
3. **Rethink Your Cost Models:** A 3x latency reduction can translate into significant cost savings or, more excitingly, enable entirely new product features.
If you can serve three times as many requests on the same hardware, or deliver a faster experience, the ROI is clear.
This changes the economic equation for deploying increasingly larger and more capable models. What was too slow or too expensive for production just 18 months ago might now be within reach.
4. **Prepare for a More Complex Deployment Landscape:** As we push towards more sophisticated AI systems, the era of monolithic model deployments is ending.
Solutions like DSpark signal a future where inference pipelines are highly optimized, multi-model orchestrations.
Start building your MLOps capabilities to handle this complexity now, focusing on robust monitoring, A/B testing for different draft models, and seamless model updates.
DSpark, and the broader push in speculative decoding, isn't just about faster text.
It’s about making the next generation of AI — the truly large, capable models that hint at AGI — economically viable for real-time interaction.
By mid-2027, I expect frameworks like DSpark to be table stakes for anyone deploying serious LLM applications.
The barrier to entry for high-performance AI is about to get a lot lower, and those who adapt first will define the applications of tomorrow.
Are you already experimenting with speculative decoding in your LLM inference pipelines, or are these latency challenges still on your "to-solve" list?
Let's discuss your experiences and predictions for the future of LLM deployment in the comments.
---


