99% of Devs Use LLMs Wrong. This Secret Gallery Is Not What You Think.
**99% of Devs Use LLMs Wrong. This Secret Gallery Is Not What You Think.**
I spent $4,200 on API credits last month, and 90% of it was a complete waste of money.
I wasn’t building a crypto scam or a high-frequency trading bot; I was just trying to get a simple customer support agent to stop hallucinating about our refund policy.
It was 2 AM on a Tuesday in late February 2026, and I was staring at a terminal window filled with "I apologize for the confusion" loops from a Claude 4.6 instance.
I realized then that I wasn’t an AI Engineer—I was just a glorified chatterbox.
I was throwing words at a black box and praying for logic to emerge, which is the technical equivalent of wishing upon a star.

Most of us are still treating ChatGPT 5 and Gemini 2.5 like advanced versions of Google Search. We type a prompt, get a result, and if it’s wrong, we "tweak the vibes" of the instructions.
This is exactly why 99% of developers are failing to move AI projects past the prototype stage. We are obsessed with the **model** when we should be obsessed with the **system architecture.**
The Death of the "Vibe-Based" Developer
For the last eighteen months, we’ve been living in the era of "Prompt Engineering," a term that I suspect will be mocked in computer science textbooks by 2028.
We thought that if we just told the model to "take a deep breath" or "think step-by-step," it would magically solve complex architectural problems.
That approach worked when we were just asking for Python scripts or summaries of Slack threads. But as we move into mid-2026, the stakes have changed.
We are building agentic systems that have write-access to production databases and the ability to execute code in sandboxed environments.
**The "vibe-based" approach doesn't scale for reliability.** I learned this the hard way when my "Expert Coder" agent accidentally deleted a staging branch because it misinterpreted a "think step-by-step" instruction as a license to "clean up" the repository.
The model didn't fail; my architecture did.
Discovering the Secret Gallery of Patterns
Everything changed for me when I stumbled upon what I call the **LLM Architecture Gallery.** This isn't a physical place, or even a single website, but a curated collection of design patterns used by the top 1% of engineers at companies like Anthropic, OpenAI, and Vercel.
Instead of seeing a prompt as a "command," these engineers see the LLM as a **component in a larger circuit.** They don't send one massive prompt to Claude 4.6 and hope for the best.
They break the logic down into a series of interconnected nodes, creating a "Gallery" of state machines that look more like a circuit board than a chat window.
When I first mapped out my support agent using these patterns, the diagram looked like a work of art. There were feedback loops, classifiers, routers, and "critic" nodes.
It was no longer a conversation; it was a **cognitive architecture.**
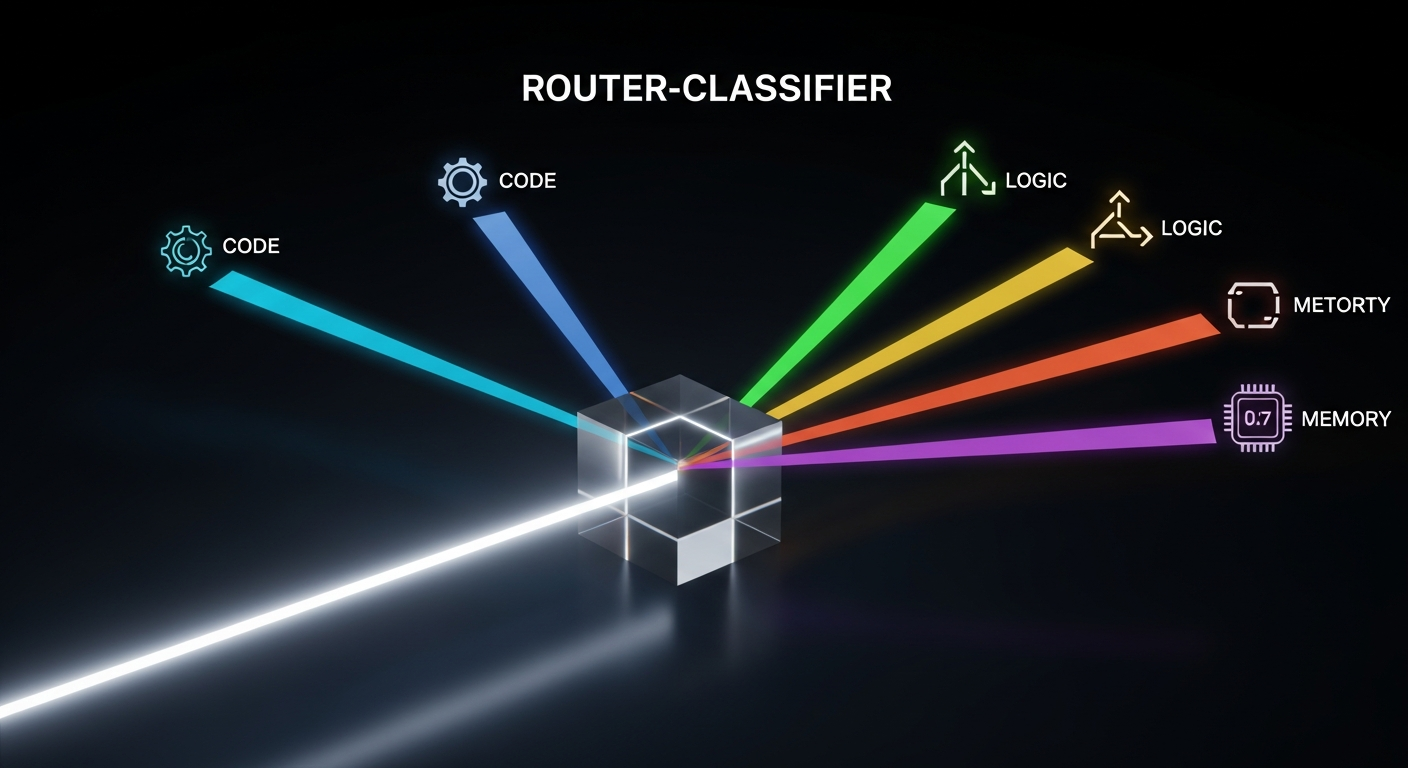
Pattern 1: The Router-Classifier-Executor
Most devs send every request to the most expensive model available. They ask ChatGPT 5 to tell them the current time or to format a JSON string.
This is like hiring a PhD in Physics to help you move a couch—it's expensive, slow, and overkill.
The first pattern in the Gallery is the **Router.** You use a small, fast, and cheap model—think a distilled version of Gemini 2.5—to act as a traffic cop.
Its only job is to categorize the user's intent.
If the user wants a simple fact, the Router sends the request to a RAG (Retrieval-Augmented Generation) pipeline. If the user wants a complex code refactor, it routes to Claude 4.6.
This simple shift reduced my latency by 60% and my costs by nearly half. **We have to stop treating LLMs as a monolith and start treating them as a tiered utility.**
Pattern 2: The Self-Correction Loop (The "Critic" Node)
The biggest secret of the 1% is that they never trust the first output an LLM gives them.
Even with ChatGPT 5, the model is prone to "logical drift" where it starts a sentence correctly but hallucinates the conclusion to maintain grammatical flow.
The "Secret Gallery" pattern for this is the **Iterative Refiner.** You have Model A generate the code, and then you have Model B (the Critic) look at that code with a completely different system prompt.
The Critic isn't asked to "fix" the code; it's asked to find three reasons why the code will fail in production.
Then, you feed those failures back to Model A. It sounds redundant, but this loop is how you get from 80% accuracy to 99.9%.
**In the world of 2026, the best way to use an AI is to have another AI tell it why it’s wrong.**
Pattern 3: The Skeleton-of-Thought
We’ve all seen it: you ask an LLM for a 2,000-word technical guide, and by paragraph four, it starts repeating itself.
This happens because the "context window" is being filled with its own previous output, and the model loses the thread of the original goal.
High-level architects use the **Skeleton-of-Thought** pattern. First, the model generates an outline (the skeleton).
Then, the system spawns parallel processes to fill in each section of the outline independently. Finally, a "Consolidator" node stitches them together and ensures a consistent voice.
This parallelization is how we get massive, high-quality documentation in seconds. It’s not one "long" thought; it’s twenty "short" thoughts coordinated by a central plan.
**If you aren't parallelizing your AI's reasoning, you're living in 2023.**
Why Your "Agent" Is Just a Script in Disguise
There is a lot of hype right now about "Agents," but most of what I see on GitHub is just a Python `while` loop with a prompt inside.
That isn't an agent; that's a fragile script that will break the moment the LLM decides to use a different emoji.
True agency requires **Environmental Feedback.** The models in the Gallery are connected to "Tools" that provide real-world state.
If my agent tries to run a command and it fails, the error message becomes part of the next prompt.
This is the "Secret" that the 99% are missing. They are trying to make the prompt "perfect" so it never fails.
The 1% realize that **failure is a data point.** They build architectures that embrace errors, catch them, and use the LLM to navigate around the obstacle.
The Cost of Ignorance in the 2026 Market
By the end of this year, the "Prompt Engineer" will be as obsolete as the "Web Portal Designer." As models like Claude 4.6 and ChatGPT 5 become more commoditized, the value isn't in knowing how to talk to them—it’s in knowing how to **wire them together.**
I see developers every day who are still trying to "fine-tune" their way out of architectural problems.
They think if they just train a model on their specific data, it will magically understand their business logic.
In reality, a well-architected RAG system with a basic model beats a fine-tuned "black box" 9 times out of 10.
**We are moving from the era of "AI Magic" to the era of "AI Engineering."** If you don't understand how to build a state machine for your LLM, you're going to be replaced by someone who does—or worse, by an agent that was built using the very patterns you’re ignoring.
How to Start Building Your Own Gallery
You don't need a PhD to start using these patterns. Start by looking at your most complex prompt and asking: "Can I break this into three smaller steps?"

Stop asking for the "final answer" in one go. Build a "Planning" node. Build a "Verification" node.
Use different models for different tasks—use Gemini 2.5 for its massive 2-million-token memory, but use Claude 4.6 for the actual logic.
When I finally implemented these changes, my $4,000 API bill dropped to $1,100, and my support agent actually started *solving* tickets instead of just apologizing for them.
The "Gallery" isn't a secret because people are hiding it; it’s a secret because most devs are too busy "tweaking vibes" to look at the blueprints.
**Are we building software that thinks, or are we just teaching machines to lie to us more convincingly?** The answer depends entirely on the architecture you choose to build.
Have you started moving away from "single-prompt" apps toward more complex agentic architectures, or are you still finding success with basic prompting?
Let's talk about the patterns that are actually working for you in the comments.
***
Story Sources
From the Author



Hey friends, thanks heaps for reading this one! 🙏
If it resonated, sparked an idea, or just made you nod along — I'd be genuinely stoked if you'd show some love. A clap on Medium or a like on Substack helps these pieces reach more people (and keeps this little writing habit going).
→ Pythonpom on Medium ← follow, clap, or just browse more!
→ Pominaus on Substack ← like, restack, or subscribe!
Zero pressure, but if you're in a generous mood and fancy buying me a virtual coffee to fuel the next late-night draft ☕, you can do that here: Buy Me a Coffee — your support (big or tiny) means the world.
Appreciate you taking the time. Let's keep chatting about tech, life hacks, and whatever comes next! ❤️